Лучшие ресурсы для изучения html и css. HTML: Абсолютные и относительные ссылки
Здравствуйте, уважаемые читатели блога сайт. Сегодня хочу затронуть тему формирования уникальных URL адресов в интернете и рассказать про принципы создания относительных и абсолютных ссылок .
Конечно же, тема формирования Урлов или их более расширенной версии URI (ури) довольно сложна, если копать глубоко и пытаться добраться до истины.
Но нам этого и не нужно, ибо достаточно понимать структуру URL в ее прикладном применении.
Ну и также, я думаю, будет полезно понимать, для чего и как можно создавать относительные ссылки для своего ресурса, а не использовать для этих целей абсолютные, когда в этом нет явной необходимости.
Урл адреса — что это и как они влияют на индексацию сайта
Итак, давайте посмотрим что такое URL, зачем он нужен и из каких частей состоит. Как вы знаете, поисковые системы производят ни как единого целого, а как совокупность отдельных страниц. Они потом будут по различным поисковым запросам (читайте подробнее о подборе ключевых слов в Вордстате на основе .
URL и URI
Ну так вот, любой документ (вебстраница) в сети интернет имеет свой уникальный адрес URL , который расшифровывается как Uniform Resource Locator (определитель местонахождения ресурса). Он, равно как и протокол HTTP, а еще и как , был разработан и создан одним и тем же человеком — Тимом Бернерсом-Ли (отцом основателем проекта ).
По большому счету URL является частным случаем другого идентификатора под названием URI (Uniform Resource Identifier — унифицированный идентификатор ресурса), но нам с вами все эти тонкости, скорее всего, будут не нужны (излишни) при работе со своим сайтом. Давайте попробуем в общих чертах разобраться с тем, что это такое и из каких частей он состоит, а потом перейдем к относительным и абсолютным ссылкам.
URL адрес — это способ однозначно указать на что-то в интернете. Он используется не только для работы с сайтами () по протоколу http (еще и по ftp), но нас, конечно же, будет интересовать именно применение этого идентификатора к Web (протоколы http и https). Урл в этом случае будет выглядеть примерно так (чуть ниже я приведу общую блок-схему его построения, но пока хотелось бы начать с простого частого примера):
Https://.html
В этом примере адреса часть с «http» обозначает протокол передачи данных или же, если следовать терминологии спецификации, схему (ибо тот же не является протоколом передачи данных, в отличии от http или ftp, но тоже используется в Урл адресах)..сайт») — или же .
WWW и другие зеркала сайта, которые нужно склеить
В Web-е есть специфика обозначения доменного имени в URL адресе сайта, которое может быть с WWW или без WWW. Для того, чтобы успешно можно было , очень важно склеить эти два зеркала вашего сайта . Зачастую, склейку зеркал за вас может выполнить хостер, но это обязательно нужно будет проверить.
Т.е. для поисковиков сайты с WWW или без оного являются абсолютно разными и без их склейки, ссылочная масса будет делиться между ними в неизвестной вам пропорции. WWW в адресе по своей сути — это некий атавизм, который делает ваше доменное имя второго уровня доменом третьего.
Тоже справедливо и при переезде сайта на защищенный протокол https с http — для поисковиков это будет уже другой сайт.
Ничего плохого в использовании WWW в URL сайта нет, но нужно четко определить главное зеркало (через и через , а также через прописывание директивы вашего сайта), которое будет индексироваться поисковиками и которое будет участвовать в ранжировании.
Е. «без атавизма», и если вы добавите к любому моему Урлу эту чудо-приставку, то произойдет автоматическое перенаправление на адрес «без WWW».
Https://www..html
Склеить можно не только описанные выше зеркала, но и любые другие доменные имена, принадлежащие вам. Например, если возможно различное написание латинскими буквами какого-либо известного бренда, то покупаются все возможные домены (варианты написания с ошибками, в разных доменных зонах и т.п.) и склеиваются между собой. Тогда, при обращении к сайту по любому из возможных URL адресов, будет открываться главное зеркало.
Например, на рег.ру можно посмотреть свободные для регистрации потенциальные зеркала или освобождающиеся домены (можете вводить предполагаемое имя домена прямо в приведенную ниже форму):
Откуда берутся лишние URL-адреса (дубли страниц) вашего сайта в индексе поисковиков
Но вернемся к нашим баранам. Та часть URL, которая расположена за третьим слешем (/) — в нашем примере это «papka/fail.html» — называется путем до конкретного объекта (документа или файла). В нашем случае это документ «fail.html», который лежит в каталоге «papka», который в свою очередь лежит в корневой папке (корень в Урле всегда соответствует третьему слешу слева).
Но это еще не все, что может быть записано в адресе. Посредством URL различные передают так называемые GET параметры, которые добавляются в самый его конец после простановки знака вопроса, например, так:
Https://www..html?print=yes
Вся беда в том, что для поисковых систем два таких URL адреса (с и без Get параметров) являются абсолютно разными веб документами и каждый из них будет проиндексирован поисковиками.
К одному и тому же Урлу может добавляться вашей Cms сколько угодно много различных Get параметров и все это будет проиндексировано Яндексом и Гуглом, если вы не создадите соответствующие запреты в файле robots.txt, ссылка на статью про который приведена чуть выше. В противном случае поисковики вас могут за большое количество дублированного контента (одного и того же содержимого, доступного по разным адресам).
Также, например, к главной странице моего ресурса можно обратиться по двум разным Урлам:
Https://сайт https://сайт/index.php
(даже по трем — еще и https://сайт/) и в любом случае откроется главная страница. Это довольно плохо, т.к. поисковики найдут у меня три разных страницы (имеющих с их точки зрения разные URL адреса), но с одинаковым содержанием, что им, ох как не нравится.
Поэтому у меня сделано так, что при вводе любого из приведенных чуть выше Урлов будет выполнено перенаправление на URL вида «https://сайт/». Делается это, как правило, с помощью 301 редиректа в файле.htaccess, либо напрямую в настройках сервера вами самими, либо вашим хостером.
Гораздо больше информации читайте в приведенной по ссылке публикации.
Структура Урл адреса и перекодировка в URL-encoded
Вообще, полную блок-схему URL адреса можно представить так:
В реальности, как правило, не используют логин, пароль и порт, хотя для доступа на платные сайты может понадобиться их указание:
Http://login:pass@сайт/platniy-dostup.html
Также довольно часто устанавливают пароли для входа на Ftp сервер , где так же может использовать не стандартный порт, а отличный от используемого по умолчанию для этого протокола. Тогда для доступа к ресурсам такого Ftp сервера потребуется вводить подобный URL:
Ftp://login:pass@сайт:6789/samoe-nujnoe/cimus
Про GET параметры, которые могут прописываться в этом адресе после знака вопроса, мы уже говорили и упоминали, что следует обязательно запрещать к индексации страницы, в Урлах которых имеются подобные параметры (выше приведена ссылка на статью про роботс, где все это подробно расписано).
Урл адреса в виде хеш-ссылок, открывающие страницу в нужном месте
Но кроме всех этих вещей, которые могут входить в состав URL, на приведенной чуть выше блок-схеме вы можете видеть так называемый якорь , который добавляется в самом конце после разделяющего символа решетки «#» (Урлы, содержащие якоря, обычно называют хеш ссылками ).
Якоря заранее проставляются внутри Html кода документа (страницы) с помощью добавление атрибута ID="метка" в нужный Html тег (абзаца, заголовка или другой подходящий), а затем, добавив название этого якоря к URL адресу страницы через символ решетки «#», вы сможете перейти не на начало этой вебстраницы, а сразу к тому месту, где был проставлен якорь (все автоматически прокрутят страницу до нужного места).
Про , и в том числе про организацию навигации на странице с помощью , читайте в этих статьях.
Какие символы можно использовать в URL адресах?
Еще стоит сказать о различных кодировках, которые используются в URL адресах. Без перекодирования в них можно использовать только ограниченное количество символов. Обычно советуют ограничиться набором из символов: ,,,[_],[-].
Вообще, во избежании ошибок, я бы советовал задавать название файлов и Урлов страниц своего сайта в нижнем регистре, ибо для юникс подобных систем (на которых работает большинство веб серверов) символы в верхнем и нижнем регистре являются разными (в отличии от Windows). Из-за разных регистров может возникнуть никому не нужная путаница.
Использование каких-либо других символов (включая русские) в урлах допустимо, но при этом будет происходить перекодировка этих самых символов (URL Encoding).
Что опечаливает, так это неудобоваримый вид URL адресов с символами, например, кириллицы, которые получаются после перекодировки. Каждый символ кириллицы кодируется с помощью двух байт в , записанных в шестнадцатеричном виде и разделенных знаком процента «%». Например, такой Урл:
Https://сайт/кто на новенького/
после перекодировки станет таким:
Http//сайт/%BA%D1%82%D0%BE%20%D0%BD%D0% B0%20%D0%BD%D0%BE%D0%B2%D0%B5%D0%BD%D1%8C%D0%BA%D0 %BE%D0%B3%D0%BE
В общем, получается не очень здорово и с этим неудобоваримым видом URL на национальных кодировках планируют разбираться и бороться, но движется это дело не ахти как быстро.
В связи со всем вышесказанным я бы советовал при на своих CMS не делать адреса страниц на русском , а , тем более, что по мнению многих продвиженцев так будет лучше в плане Seo оптимизации под Яндекс и Google.ru.
Относительные и абсолютные ссылки на сайте
Давайте начнем с абсолютных ссылок , т.к. в этом случае ничего особенного, сверх того, что мы уже обсудили в данной статье, говорить и не придется. Т.о. абсолютная ссылка должна соответствовать тем требованиям, которые мы предъявляем к URL адресу — должен указываться протокол передачи данных, доменное имя сайта (хоста) и путь до нужного web документа. Все.
В Html абсолютная ссылка формируется с помощью специальных тегов A (гиперссылки), т.е. для ее проставления мы просто должны будем окружить открывающим и закрывающим тегами гиперссылки нужное место в тексте документа (фразу или картинку) и прописать в открывающем теге A в атрибуте «Href» абсолютный путь до того документа, на который должен будет попасть посетитель при переходе по ней:
ПхпМайАдмин
Все очень просто.
Чем хороши относительные ссылки и как их можно получить
Однако, абсолютные гиперссылки обычно используют только в тех случаях, когда хотят сослаться на внешние сайты, а для внутренних переходов большинство вебмастеров (умных и прозорливых, не таких как я 🙂) стараются использовать относительные ссылки . И это есть несколько причин:
- Относительные ссылки по определению более короткие и не загромождают, не утяжеляют код сайта (ведь в этом деле важна любая мелочь).
- Кроме того, при переезде на другой домен или при смене протокола на https вам не придется менять все ссылки на сайте.
- К тому же, некоторые конструкции интернет проекта можно будет очень быстро и безболезненно перенести на другой ресурс, не изменяя при этом внутренние относительные ссылки.
Итак, если судить по названию, то адрес web документа, на который они ссылаются, должен быть прописан относительно того документа вашего сайта, из кода которого и будет проставлена данная относительная ссылка (пляшем от печки). Второй вариант их простановки заключается в использования в качестве точки отсчета корневой папки. Вот именно эти два способа создания относительных ссылок мы сейчас и рассмотрим.
Создаем относительные ссылки относительно документа, из которого они проставляются
Самый простой и короткий вариант записи относительного пути (имеется в виду значения атрибута Href тега гиперссылки) получится в том случае, когда оба web документа: донор (с которого она проставляется) и акцептор (файл или web документ, на который она ведет), находятся в одной папке на сервере.

анкор
Теперь давайте предположим, что документ акцептор лежит в папке, которая расположена в одной директории с документом донором.

Как в этом случае будет выглядеть относительная ссылка? Все тоже довольно просто:
анкор
Пока, думаю, что все понятно — прописываем путь до файла или документа акцептора (название папки, а через прямой слеш «/» имя файла или документа). Т.е. нам для того, чтобы попасть от донора к акцептору, нужно будет открыть папку, название которой мы и указываем в относительной ссылке.
Теперь давайте рассмотрим противоположную ситуацию, когда внутри папки лежит сам документ донор, с которого нужно проставить относительную ссылку на документ или файл акцептор, который уже лежит на уровень выше:

Для того, чтобы нам от документа донора пройти к файлу (или документу) акцептору, потребуется подняться из этой папки на уровень выше . Для этого предусмотрен специальный элемент — две точки подряд , а затем через прямой слеш прописывается дальнейший путь к акцептору. Поэтому для приведенного выше примера относительный путь будет иметь вид:
Что такое URL адреса
Если вам понадобится подняться на два уровня вверх, то запись будет иметь вид:
Что такое Урл
Ну, а если после этого для прописывания относительного пути до акцептора вам нужно будет еще войти в какую-либо папку на втором верхнем (относительно документа донора) уровне:

Сложная конструкция пути
Таких спусков в папки и подъемов на уровень вверх может быть сколь угодно много, главное, чтобы вы сами не запутались.
Создание ссылки относительно корневой папки
Все рассмотренные выше ссылки мы писали относительно того документа донора, с которого проставляется гиперссылка, но можно в качестве точки отсчета взять корневую папку сайта. Корень в обозначении относительных путей выглядит как одиночный прямой слеш «/».
Т.о. переход на главную страницу будет выглядеть довольно просто, но экстравагантно:
анкор
Например, абсолютный путь может выглядеть так:
анкор
А относительный до того же самого файла будет уже несколько короче:
Текст
Как сослаться на папку в относительном и абсолютном виде
Хочу обратить ваше внимание на один нюанс, который стоит учитывать при создании как абсолютных, так и относительных ссылок. Если вы хотите сослаться на папку , то обязательно ставьте в конце такой гиперссылки (после ее названия) прямой слеш «/». Т.е., если я хочу открыть содержимое папки, то мне следует написать:
анкор
А не такую:
текст
Во втором случае, при обработке, сервер будет сначала пытаться найти файл с именем «uploads» (именно такой без каких-либо расширений) и не найдя его уже потом будет искать такую папку. Поэтому, написав сразу же слеш после названия нужной вам папки , вы не будете отнимать лишние ресурсы у вашего сервера на поиски того, чего там нет.
Также следует знать, что при обращении в относительной или абсолютной ссылке к папке, веб сервер отобразит так называемый индексный файл, который лежит в ней и который, как правило, называется либо index.html, либо index.php. Если индексного файла в папке не будет, то при неправильно настроенной на сервере безопасности вы увидите листинг ее содержимого, что может привести к снижению безопасности вашего ресурса.
Обязательно , если обнаружите.
Кстати, обращение к главной странице сайта тоже по своей сути есть обращение к папке (корневой), и при этом будет запущен индексный файл лежащий в корне (в моем случае это index.php). Так вот, если вы обращаетесь к папке, то для снижения нагрузки на сервер лучше прописывать после доменного имени прямой слеш:
Вот оно чё, Михалыч!
Удачи вам! До скорых встреч на страницах блога сайт
Вам может быть интересно
 Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) - как исправить проблему с кракозябрами
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) - как исправить проблему с кракозябрами
 Как я увеличил посещаемость на сайте до 300 человек в день?
Как я увеличил посещаемость на сайте до 300 человек в день?
 Поиск Яндекса по сайту и интернет-магазину
Поиск Яндекса по сайту и интернет-магазину
 Карта сайта Sitemap в формате xml для Яндекса и Google - как создать сайтмап в Joomla и WordPress или в онлайн генераторе
Карта сайта Sitemap в формате xml для Яндекса и Google - как создать сайтмап в Joomla и WordPress или в онлайн генераторе
, умения , финансы, время, связи и т.д. Используя ресурсы, человек ухудшает свое состояния , понижается его эффективность и успешность . Чтобы улучшить состояние, нужно восстанавливать и развивать личные ресурсы : физические, духовные, интеллектуальные, финансовые и социальные.
Физические ресурсы
Отвечают за физическое состояние человека, необходимое для выполнения физических действий и оказания воздействия на окружающую среду с оптимальной эффективностью. Для восстановления этих ресурсов требуется следующее:
Здоровое питание . Существуют полезные и вредные для здоровья продукты. Использование в рационе вредной еды провоцирует множество заболеваний: ожирение, инфаркты и инсульты из-за повышенного содержания холестерина в крови и т.п. Следует минимизировать, а лучше исключить из рациона такие вещества как соль, сахар, острое, жирное, жареное и т.п. Существует множество методик здорового питания, но ими пользуется крайне мало людей.
Отказ от вредных привычек . Курение, алкоголь и т.п. также создают проблемы со здоровьем: рак легких, цирроз печени, инфаркт и т.п. Для обеспечения отличного здоровья и долголетия нужно отказаться от этих привычек.
Отдых . Выполнение работы долгое время (по 12-14 часов в сутки) приводит к переутомлению, стрессу , срывам и психическим заболеваниям. Нагружая организм продолжительное время, появляются заболевания суставов и мышц: артроз, артрит и т.п. Для избегания подобных проблем требуется регулярный отдых. Как минимум нужно спать не 3-5 часов в сутки, а полноценных 8. Отдых делиться на пассивный и активный. Пассивный отдых (полежать на диване, посмотреть телевизор, почитать книгу..) позволяет восстановить физические силы. Активный же отдых (спорт, хобби, прогулки, путешествия...) позволяет восстановиться эмоционально. Можно применять следующий принцип : лучший отдых от работы - это выполнение другой работы. Переключайтесь между работами с разными нагрузками, например, походив несколько часов по разным офисам, можно несколько часов посидеть за своим столом и выполнить бумажную работу, разобрать почту, составить отчеты и т.п.
Для развития физических ресурсов нужно выполнять физические упражнения, повышающие силу, выносливость и гибкость тела. Посещение тренажерного зала или наем опытного тренера не является обязательным условием для этого - достаточно заниматься дома по 20-30 минут в день. Но многие люди обманывают себя, говоря что такие занятия не обязательны для выполнения основной работы, а следовательно являются бесполезными. Но они сильно заблуждаются, т.к. эти дела полезно влияют на здоровье и продлевают срок нормального функционирования тела.
Не развивая физические ресурсы, обязательно ухудшится здоровье, что значительно снижает успешность и эффективность. А сокращение продолжительности жизни приведет к тому, что человек может не успеть реализовать свое предназначение .
Духовные ресурсы
Духовные ресурсы определяют направление движения человека, вектор развития и формируют его внутренний стержень, за который он держится каждый день при принятии решений , составлении планов и постановки целей .
Интеллектуальные ресурсы
Для развития этих ресурсов требуется осознанное , методичное и целенаправленное приобретение опыта. Это происходит в детском саде, школе, колледже, вузе и других учебных заведениях. Но получив диплом, люди сводят к минимуму или прекращают самообразование. Непрерывное приобретение опыта требуется для личного развития и выполнения творческой деятельности , чтобы достичь цели жизни и реализовать личное предназначение.
Нужно регулярно изучать практические пособия, книги и журналы из предметной области, которая соответствует личному предназначению и призванию. Это дает новые знания и вдохновляет на выполнение творческой деятельности . Полученные знания нужно применять на практике для приобретения новых умений и их развития до навыков и компетенций , которые позволяют заниматься творческой деятельностью с оптимальной эффективностью.
Финансовые ресурсы
Когда человек достигает очередной цели, он получает некий результат , который может обменять на их универсальный аналог - деньги . Они являются неким посредником и позволяют обменять уже имеющиеся результаты на ресурсы для новых целей, что повышает эффективность и успешность их достижения. Важны не только деньги, но и экономические отношения, которые и позволяют производить обмен результатов на деньги и денег на ресурсы. Для повышения эффективности таких отношений существуют финансовые институты - банки, биржи, рынки, инвестиционные и страховые компании и т.п., которые объединяют людей с результатами, деньгами и ресурсами в единое пространство, что значительно ускоряет обменные процессы между ними.
Для развития финансовых ресурсов необходимо постоянно повышать доходы и капитал и понижать расходы. Разницу между доходами и расходами всегда необходимо вкладывать для увеличения доходов: "капитал должен приносить капитал". Как минимум следует начать с откладывания процента от доходов на банковский вклад. Генерируйте идеи для организации нового бизнеса и повышения доходности инвестиций. В этом поможет мощный сервис Бесплатный онлайн органайзер, ежедневник, планировщик дел и задач, календарь - Личные цели .
Наличие развитых финансовых ресурсов делает человека свободным от денежных проблем. Ему не нужно выполнять неприятную работу только для того, чтобы получить деньги на еду и одежду. Он может сконцентрироваться только на личных целях для достижения успеха и реализации своего предназначения. Только в таких условиях человек может испытывать счастье .
Социальные ресурсы
Человеку для достижения целей требуется определенный опыт . Если его нет, то он может приобрести его самостоятельно. Но есть и другой вариант – установить социальные отношения с людьми, которые уже обладают этим опытом и которые помогут разобраться с проблемой, делом или целью на взаимовыгодных условиях . Взаимодействуя с такими людьми, человек повышает личную эффективность за счет взаимопомощи.
Например, есть автослесарь и электрик. Если у первого сломается телевизор, а у второго - автомобиль, они могут помочь друг другу и первый отремонтирует автомобиль, а второй - телевизор, естественно, на взаимовыгодных условиях.
Чем больше у человека связей с разными людьми, обладающими разным опытом, тем больше у него социальных ресурсов для более успешной и эффективной реализации личного предназначения.
Научитесь делать первый шаг к достижению успеха
с помощью тренинга
Тренинг уверенности в себе
Научитесь придумывать способы развития личных ресурсов
с помощью тренинга
Как правило, многие вебмастера загружают свои сайты на хост сразу-же после их создания. При этом они большей частью ориентируются на правильность составления смысла текстового содержания, чем на правильность внутреннего кода страниц.
Валидация сайта
Но есть и другие факторы, которые могут и влияют на позиции сайта. И к ним относятся, в том числе, и технические факторы. Ну а к техническим относятся и валидация сайта. Так что же это такое?
Если простыми словами, то валидация сайта — это проверка кода сайта на техническое соответствие и ошибки. Ну например, вы забыли использовать закрывающий тег — /html. В последнем HTML5, визуально ничего не поменяется. Однако, это ошибка кода.
При написании кода, возможны и другие ошибки. И опять-таки, современный язык гипер разметки «стерпит» многое. Например, «забытие» закрывающего тега /head. И снова вы не увидите разницу. Но она есть))
На самом деле, при написании сайта, ошибок может быть довольно много. И что хуже, некоторые из этих ошибок, могут проявиться и визуально. Ну может блоки поплывут, может выравнивание, а может и еще что-то. Потенциальных ошибок, тысячи. И далеко не все из них, бросаются в глаза.
В чем опасность?
Ну казалось-бы, ну и что тут такого? Да, нужно сказать, что зачастую такие ошибки не видимы. Точнее, невидимы человеком. А ведь страницы нашего сайта могут посетить не только люди, но и поисковые пауки, которые полностью просматривают сайт. И каждую ошибку, которую они находят на сайте, они передают на сервера поисковиков, таких как Яндекс или Гугл.
А поисковики, в свою очередь, видя что на сайте много ошибок кода, вполне могут сделать вывод о том, что сайт плохой. И значит, не будут поднимать его в поиске. Ну а это уже будет означать, что прощай посетители с поиска.
Да, надо признать, определенная пессимизация сайта из-за ошибок валидации, это довольно редкое явление. Но это вполне возможно, а значит, над валидацией обязательно нужно работать. А что для этого нужно сделать? Понятное дело, вначале ошибки нужно найти.
Но поскольку вручную это очень трудоёмкое и ненадежное дело, то для поиска ошибок, используются специальные сервисы, так называемые «Валидаторы».
Валидатор Markup Validation Service.
Этот сервис проверяет правильность кодов HTML и XHTML, которые являются основой большей части страниц при создании практически любого сайта и определяют его внутреннюю структуру. На этот сервис валидатора можно попасть, если пройти по ссылке http://validator.w3.org
Но здесь есть обязательное условие, которое также относится и к другим валидаторам: проверяемый сайт или его проверяемые страницы должны быть закачаны на хостинг. В противном случае, валидатор не будет «знать» адрес сайта и не сможет ничего проверить. Вот сейчас можно уже рассмотреть, как работать на этом валидаторе.
После захода на страницу этого сервиса, отобразиться вся его функциональная картинка. Но большая часть изображённого и написанного к основной проверке не относится и всё своё внимание надо обратить только на окно ввода адреса проверяемой страницы:
Вот именно с него и надо начинать.
Вообще-то, проверка валидации сайта чрезвычайно проста, как и весь наш бренный мир: в адресном окне сервиса надо написать адрес сайта, т.е. его URL и затем нажать «Check». После такого простого действия, валидатор «попыхтит» несколько секунд и выдаст следующее:
Это означает, что никаких ошибок в коде страницы нет и Вы можете быть абсолютно спокойны.
Но также может быть и такой нежелательный вариант:
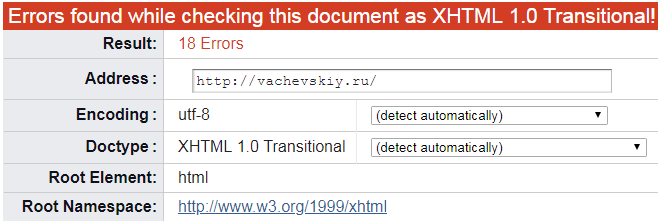
Это уже похуже и означает, что во внутреннем коде проверяемой страницы есть какие-то ошибки. Однако, это совсем не смертельно: просто надо прокрутить страницу ниже и там подробно будут написаны все найденные ошибки в процессе проверки.

Кроме того, валидатор не только перечислит найденные ошибки, но и точно покажет, на какой строке внутреннего кода эти ошибки расположены. Так что долго их искать не придётся. Здесь, ничего не преувеличивая, можно твёрдо сказать, что этот валидор работает прекрасно.
Но это ещё не всё: валидатор не только указывает местоположение обнаруженной ошибки кода, но и даёт достаточно полные рекомендации, каким образом можно устранить эти ошибки. Конечно, для этого не надо лениться и внимательно прочитать всё написанное.
В качестве краткого и обобщенного вывода, можно сказать следующее:
- данный сервис валидатора работает прекрасно и может очень быстро провести проверку сайта.
- Ну и небольшое, но очень приятное дополнение: валидация сайта производиться бесплатно.
- Сейчас можно перейти к следующему этапу: это проверка кода CSS.
Валидатор CSS Validation Service
В общем это вторая функция вышеописанного сервиса, но она «заточена» не для проверки кода HTML и XHTML, а конкретно для проверки правильности кода стиля CSS, расположенного на внешней таблице. А чтобы попасть на страницу сервиса, надо пройти по ссылке http://jigsaw.w3.org/css-validator .
Кстати, здесь стоит отметить нечто приятное: проверка на этом сервисе абсолютно бесплатна. Так что не надо вытаскивать деньги из своего кошелька — пусть они лежат до нужного момента. Однако перейдём к методике работы на этом втором сервисе.
В общем-то вся работа на валидаторе CSS абсолютно идентична проверке на чистоту кода. Поэтому, приводить отдельную картинку адресной строки валидатора нет необходимости. Просто чуть ниже кратко рассмотрим непосредственно порядок самой проверки и всё.
Для этого надо в адресной строке записать URL таблицы CSS, типа «http://мой сайт/style.css» и после этого нажать кнопку с русской надписью «Проверить». Соответственно, этот валидатор тоже несколько секунд «попыхтит» и выдаст искомый результат:
Это значит, что таблица CSS написана правильно и никаких ошибок в ней не обнаружено.
И здесь также есть приятная неожиданность: если прокрутить страницу несколько ниже, то там будет написан оптимизированный код для Вашей таблицы CSS, из которого убраны все лишние надписи и все теги кода будут расставлены в той последовательности, которая соответствует оптимальным рабочим требованиям всех поисковых систем. Остаётся только скопировать этот идеальный образец кода и вставить его в таблицу CSS.
Вполне может быть, что случиться и такой вариант:

Это значит, что обнаружены какие-то ошибки в коде CSS, но пугаться этого совсем не стоит. Сразу внизу под этой красной строкой, валидатор точно укажет, какой тег написан неправильно. Остаётся только в таблице стиля найти эти теги и сделать нужные исправления.

И конечно, после этого закачать исправленную таблицу стиля на хост и при наличии зелёной строки можно с удовольствием скопировать оптимизированный код стиля таблицы CSS. Вполне понятно, что затем лучше всего поменять старый код на новый и оптимизированный.
Краткое резюме.
Выше были рассмотрены две самых основных и обязательных проверки валидации сайта. Без этих проверок даже не стоит открывать индексацию для поисковых систем в robots.txt В противном случае, сайт может быть проигнорирован для индексации поисковыми машинами и будет считаться неисправным с соответствующими санкциями.
Чтобы этого не произошло, надо затратить всего несколько минут, чтобы быть абсолютно спокойным и полностью уверенным в техническом состоянии своего сайта и всех его страниц. Конечно, необходимо ещё произвести дополнительные проверки ссылок и анкоров, видимости сайта на мобильных устройствах и параметры других кодов. Только тогда сайт можно считать готовым для его полного функционирования и для удачного и быстрого продвижению в ТОП.
Заранее хочется сказать, что все остальные проверки проходят также быстро и просто, как и рассмотренные выше — надо только внимательно прочитать порядок работы с валидатором.
Добавлено 19.04.2018г.
Распространенные ошибки валидности при проверке html кода
Решил дополнить статью ошибками HTML кода, которые часто встречаются на сайтах. Во всяком случае у меня их было много)). Сами ошибки валидатор подсвечивает желтым цветом.
1) Error: Character reference was not terminated by a semicolon.

Ошибка: символ не был прерван точкой с запятой — соответственно надо добавить.
2) Warning: Section lacks heading. Consider using h2-h6 elements to add identifying headings to all sections.
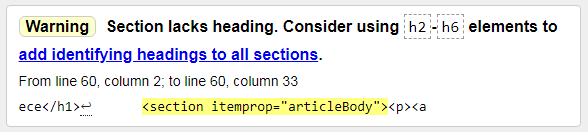
Предупреждение: Раздел не имеет заголовка. Рассмотрите возможность использования элементов h2-h6 для добавления идентифицирующих заголовков ко всем разделам. Тут все понятно, надо добавить хотя бы один подзаголовок. Это даже не ошибка, а рекомендация.
3) Error: Element noindex not allowed as child of element p in this context.
Ошибка: элемент noindex не разрешен как дочерний элемент элемента p в этом контексте. (Подавление дальнейших ошибок из этого поддерева.)
Решение простое, надо закомментировать тег ноиндекс, вид будет таким:
4) Error: The center element is obsolete.
Ошибка: тег «center» устарел — надо заменить, если речь про img то можно использовать атрибут align. Если что-то другое центрировали, то заменить на div.
5) An img element must have an alt attribute, except under certain

Ошибка: Элемент img должен иметь атрибут alt -тут все понятно, надо добавить атрибут альт, даже если он будет незаполненный, то ошибка уйдет.
6) The width attribute on the td element is obsolete. Use CSS instead.
Ошибка: Атрибут «width» на элементе «td» устарел

7) The type attribute is unnecessary for javascript resources

Ошибка: атрибут type не нужен для ресурсов javascript. Решение просто удаляем все лишнее и оставляем только тег «script».
8) The align attribute on the img element is obsolete.

Ошибка: Атрибут align для элемента img устарел. Сделайте выравнивание изображений дивами.
В последнее время неоднократно всплывает тема загрузки ресурсов. Вкратце: «Я загружаю картинку из c:\work\image.gif, а когда запускаю программу из jar-файла/на другом компьютере – она не грузится. Что делать?».
Между тем, ничего сложного тут нет. Надо только понимать принципы.
Прежде всего, грузить ресурсы по абсолютному адресу на диске – занятие бесперспективное. Думаю, сами прекрасно понимаете, почему – убрали файл с диска, и «прощай ресурс». Всё свое надо носить с собой.
Второй вариант, который я часто вижу, – загрузка ресурса из jar-файла. Но тут очень часто делается одна ошибка – ресурс пытаются грузить через класс java.io.File . При том, что этот класс предназначен только для работы с файловыми системами.
Хотя сама идея правильная. Нужный ресурс действительно необходимо поместить в jar-файл. Надо только понимать, как его оттуда загрузить. Вот об этом я и расскажу.
Для загрузки ресурса служат методы java.lang.Class.getResource(String) , java.lang.Class.getResourceAsStream(Stri ng) , java.lang.ClassLoader.getResource(String) и java.lang.ClassLoader.getResourceAsStrea m(String) . Методы Class -а делегируют вызовы ClassLoader -у.
GetResource(String) по имени ресурса возвращает java.net.URL , через который можно получить этот ресурс. getResourceAsStream(String) , как нетрудно догадаться, возвращает java.io.InputStream , через который ресурс можно прочитать.
Имя ресурса представляет собой путь к ресурсу. Есть одна существенная тонкость, а именно – как оно интерпретируется.
Имя может быть абсолютным и относительным. Внешнее отличие – абсолютное имя начинается с символа "/". В первом случае ресурс ищется относительно корня classpath. Т.е. берутся все пути и jar-файлы, входящие в classpath, и ресурс ищется относительно совокупности этих точек. Если же имя относительное – к нему в начало приписывается путь, полученный из пакета текущего класса. Далее поиск ведется как в случае абсолютного имени.
Проще это понять на примерах. Пусть у нас задан classpath: c:\work\myproject\classes;c:\lib\lib.jar . Код примера находится в классе ru.skipy.test.ResourceLoadingTest .
Пример 1 . Мы используем конструкцию getClass().getResource("/images/logo.svg") . Поскольку имя начинается с символа "/" – оно считается абсолютным. Поиск ресурса происходит следующим образом:
- К пути из classpath c:\work\myproject\classes приписывается имя ресурса /images/logo.svg , в результате чего ищется файл c:\work\myproject\classes\images\logo.pn g . Если файл найден – поиск прекращается. Иначе:
- В jar-файле c:\lib\lib.jar ищется файл /images/logo.svg , причем поиск ведется от корня jar-файла.
- К пути из classpath c:\work\myproject\classes приписывается текущий пакет класса, где находится код, – /ru/skipy/test , – и далее имя ресурса res/data.txt , в результате чего ищется файл c:\work\myproject\classes\ru\skipy\test\r es\data.txt . Если файл найден – поиск прекращается. Иначе:
- В jar-файле c:\lib\lib.jar ищется файл /ru/skipy/test/res/data.txt (имя пакета текущего класса плюс имя ресурса), причем поиск ведется от корня jar-файла.
Вот тут можно скачать полностью рабочий пример, иллюстрирующий оба типа загрузки: . Ресурсы – изображение и текст – располагаются в отдельной директории, при сборке попадают в jar-файл и грузятся один по абсолютному, другой по относительному имени. Пример собирается и запускается через ant , командой ant run он запускается из директории сборки build/classes/ , командой ant run-jar – из собранного jar-файла.
Вот, где-то так. Вопросы? Комментарии?
: всегда хотел это понять, но значимость его была настолько мала, что всегда находился повод этого не делать:)
А вы задавались вопросом: URL — что это ?
Всегда с таким сталкиваюсь, но до сих пор не желал понять в чем различие между терминами URI, URL, URN, а тут вдруг постик (к сожалению, он уже канул в Лету), решил - и сам почитаю, и другим поведаю, хотя, как сказано выше, от этого ничего не изменится, но люблю я иногда побуквоедствовать, так-что читайте толковый переводец:
Вы когда-нибудь обращали внимание на адресную строку в Вашем браузере? Что это? URI, URL или URN? Многие из нас не делают различий между URI, URL, URN, а кое-кто даже и не слышал терминов URI и URN, все просто пользуются термином URL. Давайте вместе попытаемся разобраться в этом.
Расшифровка аббревиатур
URI - Uniform Resource Identifier (унифицированный идентификатор
ресурса)
URL - Uniform Resource Locator (унифицированный определитель местонахождения
ресурса)
URN - Unifrorm Resource Name (унифицированное имя
ресурса)
Внимание, здесь в мелочах кроется истина, но пока ничего не понятно, какая-то каша. Едем дальше.
Определение
URI: Обозначает имя и адрес ресурса в сети. Как правило, делится на URL и URN, поэтому URL и URN это составляющие URI.
URL: Адрес некоторого ресурса в веб. URL определяет местонахождение ресурса и способ обращения к нему.
URN: Имя некоторого ресурса в веб. Смысл URN в том, что он определяет только название конкретного предмета, который может находится во множестве конкретных мест.
Нет ничего лучше, чем конкретный пример
URI = http://сайт/2009/09/uri-url-urn.html
URL = http://сайт
URN = /2009/09/uri-url-urn.html
Подведем итоги
URI это концепция абстрактного идентификатора, тогда как URL и URN конкретная реализация - адреса и имени.
Надеюсь всем всё понятно. Будьте грамотны!
Восприятие каждого из нас индивидуально, поэтому — спорьте и читайте обсуждения в комментариях к статье, там много чего интересного.
Статьи по теме